


In Part One, the argument was that AI is undergoing the same miniaturization arc that turned the 1980s brick phone into the supercomputer in your pocket. Pocket-sized devices running 120-billion-parameter models offline. Photonic chips doing in light what used to take racks of silicon. Architecture researchers reverse-engineering frontier models in public. The compute is shrinking, the cost is falling, and the assumptions defenders built their posture on are quietly expiring.
But while we have been watching AI shrink downward, into devices, into edge hardware, into your jacket pocket, something else is happening in the other direction entirely. The phone is not just getting smaller. It is also going to orbit.
And that changes almost everything about the GPU market, the chip supply chain, and the geopolitics of AI compute.
Terafab: The Most Ambitious Vertical Integration Play in Semiconductor History

On March 21, 2026, Elon Musk took the stage at the defunct Seaholm Power Plant in Austin, Texas, and announced Terafab: a $20-25 billion joint venture between Tesla, SpaceX, and xAI, with Intel joining the consortium on April 7, targeting the production of more than one terawatt of AI compute capacity per year. He described it as "the most epic chip building exercise in history by far," which, given the competitive landscape in superlatives, is saying something.
The ambition of the project is not the dollar figure. It is the scope of vertical integration. Terafab is designed to consolidate every stage of semiconductor production under a single roof: chip design, lithography, fabrication, memory production, advanced packaging, and testing. The capability to design a chip, build it, test it, revise the mask, and iterate without shipping wafers between sites does not currently exist anywhere else in the world. Not at TSMC. Not at Samsung. Not at Intel's existing fabs. The iteration speed that comes from collapsing that supply chain is Terafab's real competitive weapon.
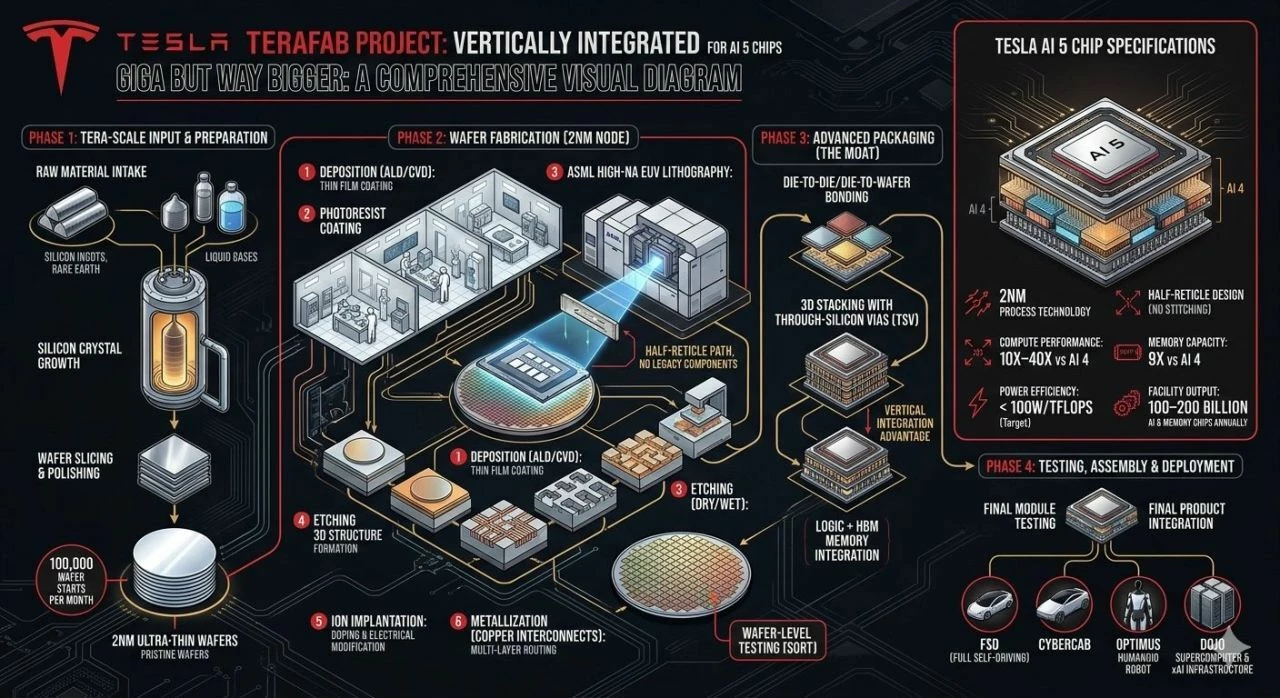
Two categories of chips are planned. The first is edge inference silicon for Tesla vehicles and Optimus humanoid robots, beginning with the AI5 in small-batch production in late 2026 and volume production in 2027. The second is a purpose-built orbital chip, the D3, designed specifically for space-based AI infrastructure operating in vacuum, radiation, and solar-power-saturated environments. The breakdown of intended production is where the announcement gets genuinely strange for anyone following conventional semiconductor logic: Musk stated that 80% of Terafab's compute output would be directed toward space, with only 20% for ground-based applications.
That is not a chip factory. That is a launch pad with a fab attached.
Solar Power and the Physics of Orbital Compute

The space compute argument Musk made at the Terafab announcement deserves more scrutiny than it has received, because the underlying physics are not as strange as they sound.
Solar irradiance in low Earth orbit runs approximately 1,361 watts per square meter, consistently and without the atmospheric absorption losses that reduce ground-level solar to roughly 250-300 W/m² under average conditions. That is roughly five times more energy available per unit of panel area. For an energy-intensive workload like large-scale AI inference, that difference is not incidental. It is foundational to whether orbital compute can undercut terrestrial compute on a cost-per-operation basis.
The question of how to cool a high-wattage compute cluster in vacuum, where convection is impossible, has historically been the stopping point for anyone who asked this question seriously. But Starcloud, an orbital data center startup that recently closed a $170 million Series A at a $1.1 billion valuation, has demonstrated something important: passive radiative cooling using the natural thermal sink of deep space can dissipate heat effectively enough to run enterprise-grade AI hardware. Their Starcloud-1 mission successfully operated an NVIDIA H100 Tensor Core GPU in a 60 kg microsatellite, delivering roughly 100 times the compute capacity of any previous orbital processor, using no active cooling whatsoever. Starcloud-2 is planned to carry NVIDIA Blackwell architecture and run commercial inference workloads.
NVIDIA itself has been moving in this direction. At a March 2026 event, Jensen Huang confirmed that NVIDIA's THOR chip is "radiation approved" and that the company is actively pursuing space-based data center capability. Their IGX Thor platform and the Space-1 Vera Rubin Module are explicitly engineered for orbit. The company that built its dominance on terrestrial AI infrastructure is hedging into the same orbital compute thesis that Musk is betting $25 billion on.
Musk's projection that orbital AI compute could become cost-competitive with terrestrial alternatives within two to three years sounds aggressive until you factor in the energy cost trajectory on the ground. Terrestrial data centers are already straining power grids and water systems. Space has unlimited solar with no permitting, no utility negotiation, and no cooling infrastructure to maintain. The economics are not fantasy. They are just further out than most quarterly-focused investors are willing to model.
The GPU Market Is Already Breaking
Before Terafab entered the equation, the GPU market was already under pressure from multiple directions simultaneously.
NVIDIA will not release a single new gaming graphics card in 2026, marking the first gap in consumer GPU releases in thirty years. The reason is not product strategy. It is allocation. Every available unit of advanced packaging capacity, high-bandwidth memory production, and TSMC/Samsung foundry time is being consumed by data center AI chip demand. H100 and H200 pricing has increased roughly 40% since March. Blackwell and the upcoming Vera Rubin architecture command 50% premiums or more. Lead times for data center GPU orders now run 36 to 52 weeks. Hyperscalers with long-term contracts get chips. Everyone else hunts the secondary market or rents compute from cloud providers at prices that reflect the scarcity.
The tariff environment has compounded this significantly. NVIDIA derives approximately 69% of its revenue from US-based customers but manufactures almost entirely in the TSMC ecosystem in Taiwan. The company took a reported $5.5 billion hit from US export licensing requirements on its H20 chip, a downgraded GPU specifically designed to be sellable to China. With US tariffs on Chinese goods sitting at 145% and semiconductor tariffs under active consideration, the supply chain that the entire AI industry depends on runs directly through the most geopolitically contested piece of real estate in global manufacturing.
NVIDIA's response has been to announce US-based domestic manufacturing, with Arizona targeted for Blackwell chip testing and Texas for AI supercomputer assembly, following the broader CHIPS Act incentive structure designed to onshore semiconductor capability. That is the right directional move. It is also a years-long project running against a market that needs chips now.
This is the environment Terafab enters. Not a stable market looking for incremental competition, but a fractured, tariff-stressed, allocation-constrained market where every major player is scrambling to secure supply and the existing infrastructure cannot expand fast enough to meet demand.
Where the Shrinking Phone and the Orbital Fab Collide
Here is where the two threads of this series converge in a way that I think the market has not fully priced in.
The thesis in Part One was that AI inference is becoming radically more efficient. TurboSparse sparsification. PowerInfer activation-locality routing. Recurrent-Depth Transformer architectures like the one OpenMythos hypothesizes for Claude Mythos, where 770M parameters do the work of 1.3B. Photonic computing from Q.ANT promising 30x energy efficiency and 50x compute density. The direction of travel is unmistakably toward doing more inference with fewer resources.
If that trend continues, and the architectural research suggests it will, then the total volume of raw compute required to serve a given AI workload at a given capability level shrinks. Not the demand for AI. The compute required per unit of AI output. Those are very different things.
Terafab is being built on the assumption that demand for compute is effectively unbounded, that Musk's claim that current global fab output represents only 2% of what Tesla and SpaceX will eventually need is approximately correct. And he may be right about the long-term demand signal. Autonomous vehicles, humanoid robots at scale, and orbital AI constellations are all genuinely enormous compute sinks.
But the efficiency revolution happening at the inference layer means the compute required to serve frontier-class AI capability from a pocket device, or from a purpose-built orbital satellite, is collapsing faster than the fab capacity is expanding. Terafab is building for a world of compute abundance to meet demand that may itself be partially satisfied by architectural efficiency gains before the fab reaches full production.
This creates a scenario that looks unusual in the history of semiconductor infrastructure: purpose-built, vertically integrated inference silicon designed specifically for edge and orbital workloads, coming online just as the efficiency of inference on that silicon is being compressed by architectural innovation. The general-purpose GPU, optimized for training workloads, may be caught in a squeeze between custom inference silicon below and orbital compute above, in a market already stressed by tariffs and allocation constraints.
NVIDIA's dominance in AI hardware is real and its moat is deep. CUDA's ecosystem lock-in alone has defeated every challenge for a decade. But the company is navigating a market where it cannot release consumer GPUs for the first time in thirty years, where tariffs threaten its most price-sensitive market segments, where China-developed alternatives are closing the capability gap, and where the two fastest-growing compute modalities, edge inference and orbital compute, are specifically the use cases that purpose-built silicon from Terafab is designed to serve.
The Geopolitical Dimension: Who Controls the Sky
From a national security perspective, the orbital compute angle of Terafab is the part worth watching most carefully.
Terrestrial AI infrastructure has geographic chokepoints that intelligence agencies understand well. TSMC is in Taiwan. Samsung is in South Korea. The supply chains for advanced packaging run through Malaysia and Japan. Export controls, tariffs, and military risk are all legible within that geography. When the US restricts NVIDIA H20 exports to China, the mechanism is understood and the effect is measurable.
Orbital compute does not have the same chokepoints. A constellation of AI inference satellites in low Earth orbit, launched on Starship, powered by solar, cooled by deep space, and running custom silicon designed for the environment exists outside the tariff regime, outside terrestrial export control enforcement, and outside the geographic risk calculus that governs current semiconductor policy.
The US, with SpaceX's launch cadence and Terafab's chip production, has a first-mover advantage in this space. But the same logic that drives Terafab applies to any nation-state with a mature space launch capability and a semiconductor development program. China's orbital launch cadence is accelerating. Their domestic chip program, accelerated by US export restrictions, is developing custom silicon outside TSMC's ecosystem. The long-range trajectory is toward orbital AI compute constellations operated by competing geopolitical blocs, with inference capacity distributed literally across the sky in ways that make the current export control framework effectively obsolete.
For the AI arms race framing I used in Part One, where the "who has the better weights" dynamic is replacing the traditional tools-and-techniques cat-and-mouse, this adds another dimension entirely. It is not just who has the better weights. It is who controls the compute fabric those weights run on, and whether that fabric is subject to any of the jurisdictional controls that currently govern AI capability proliferation.
The phone shrank into your pocket. The satellite is becoming a data center. And the geopolitics of who gets to use that data center, and from where, are only beginning to be written.
What This Means for Defenders
The practical implications for security teams operate on two timescales.
In the near term, the GPU shortage and tariff environment is creating real pressure on security budgets that rely on GPU-accelerated workloads. On-premises AI inference for security tooling, large-scale log analysis, and real-time detection models all compete for the same constrained hardware. Security teams that have been planning GPU procurement need to factor in 36-52 week lead times, 40-50% price increases on premium accelerators, and supply uncertainty that is not resolving in 2026.
On the longer horizon, the orbital compute thesis reshapes the threat model for AI-assisted attacks. The current detection posture for AI-assisted adversarial activity assumes that large-scale inference requires either cloud API calls, which leave telemetry, or significant on-premises hardware, which leaves an acquisition footprint. Pocket Lab-class devices eliminate the on-premises hardware signature. Orbital compute, available as a service from a jurisdiction outside domestic regulatory reach, eliminates the cloud telemetry trail.
The combination is what matters. A sophisticated threat actor with access to efficient local inference for initial operations and orbital compute for heavier workloads like training, fine-tuning, and large-scale reconnaissance operates in a threat model that most current detection frameworks were not designed for.
Terafab is five or more years from the orbital compute ambitions Musk described. Pocket Lab hardware is shipping to consumers this August. Photonic accelerators are operational at European supercomputing centers today. The timeline is not uniform. But the direction is consistent, and the endpoint of that direction is an AI capability landscape that looks nothing like the one the current generation of detection tooling was built against.
The phone is shrinking. The sky is getting its own server room. And the market that built its dominance on selling shovels to the gold rush is watching two very different kinds of shovels get built, simultaneously, from opposite ends of the atmosphere.
References:
- Terafab announcement: Teslarati, Electrek, Wikipedia, March 21-22, 2026
- Intel joins Terafab: International Business Times Australia, April 17, 2026
- Starcloud Series A and orbital AI: Futurum Research, April 2026
- NVIDIA space computing and THOR chip: NVIDIA Newsroom, March 16, 2026; Benzinga, March 2026
- GPU shortage and pricing: Clarifai, Yahoo Finance, Tekin Analysis, 2026
- NVIDIA tariff exposure and H20 restrictions: TechTarget, April 2026
- Tiiny AI Pocket Lab and Q.ANT photonics: See Part One references