

The proverbial phone is shrinking before my eyes.
In the 1980s, the "mobile phone" was a brick. A two-pound, briefcase-attached monument to the idea that wireless communication was possible, if inconvenient. Those who carried one weren't just making calls. They were signaling that technology had crossed a threshold. Today, you carry more compute in your pocket than existed in entire buildings forty years ago. The phone didn't just shrink. It became something unrecognizable.
AI is doing the same thing. Right now. And the cybersecurity implications are only beginning to surface.
From Cloud Cathedrals to Pocket Supercomputers
For the last several years, running a frontier-class AI model meant paying homage to the cloud. Massive GPU clusters. Enormous energy bills. Data that had to leave your network to be processed somewhere in a hyperscaler's geography. The compute was centralized by necessity, and that centralization gave defenders a chokepoint. You could watch egress. You could inspect what left.
That chokepoint is disappearing.
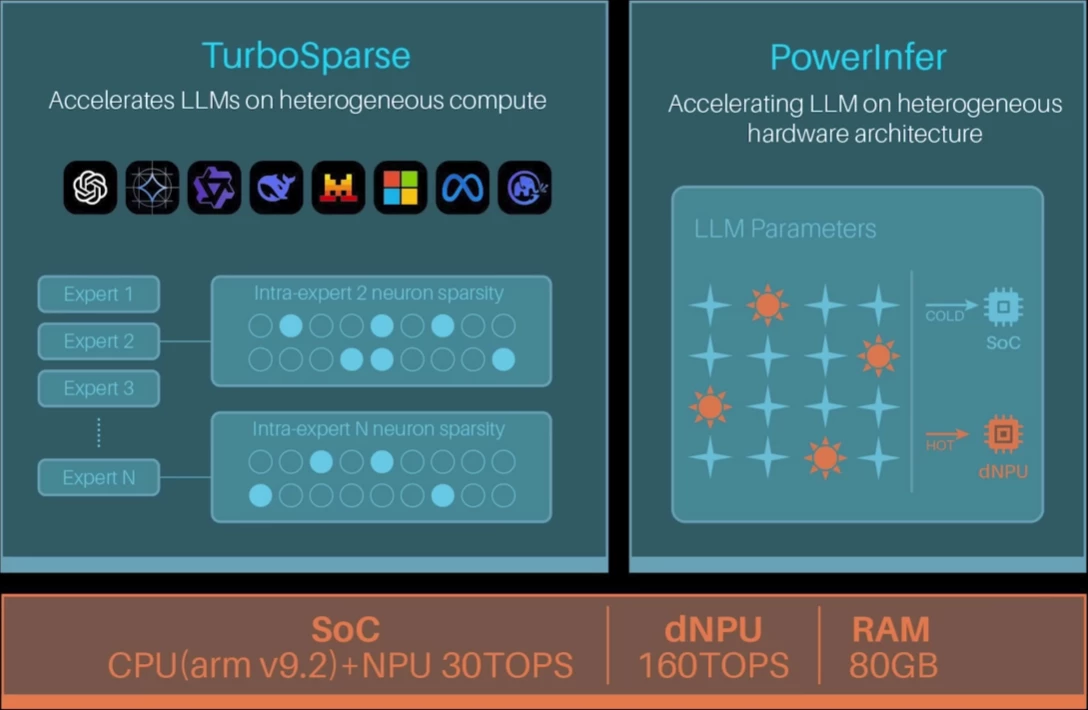
In January 2026, Tiiny AI unveiled the Pocket Lab at CES, a 300-gram device, palm-sized, Guinness World Record certified as the smallest MiniPC capable of running a 100B+ LLM locally. The spec sheet is remarkable: a 12-core ARMv9.2 CPU, a custom NPU delivering approximately 190 TOPS, 80GB of LPDDR5X memory, and a 1TB SSD, all operating at a 35W typical power draw. It runs GPT-OSS-120B at 20 tokens per second, entirely offline, with no cloud dependency whatsoever.

The engineering underpinning this is their open-source PowerInfer inference engine, which exploits something called activation locality. The insight is elegant: in any given inference pass, only a small subset of neurons, called "hot neurons," fire consistently. The rest, called "cold neurons," activate sparsely based on input. PowerInfer preloads hot neurons onto the GPU/NPU for fast access while routing cold neuron computation to the CPU, dramatically reducing memory bandwidth requirements. Pair this with TurboSparse, their neuron-level sparsification technique achieving roughly 90% sparsity with minimal performance degradation, and you get a system that delivers what used to require a rack into a form factor that fits in a jacket pocket.
The delivery timeline puts hardware in hands by August 2026 for around $1,500. Consider what that number means in the context of a threat actor budget.
Light Speed: The Hardware Revolution Underneath Everything
While Tiiny AI is compressing AI into portable silicon, another company is attacking the physics of the problem from a different direction entirely.
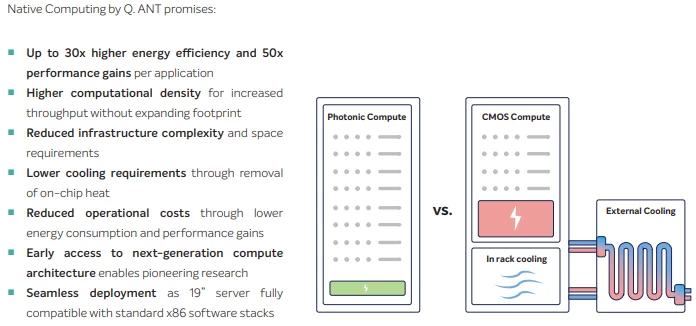
Q.ANT, a photonic computing startup, is shipping the Native Processing Server (NPS), the first commercial photonic AI accelerator for production HPC environments. It operates by performing mathematical functions natively in light, using a Lithium Niobate on Insulator (LNoI) photonic integrated circuit. Their second-generation NPU (Gen 2) is now operating at two of Europe's premier supercomputing centers: the Leibniz Supercomputing Centre (LRZ) and Jülich Supercomputing Centre (JSC).

The claimed performance envelope is striking: up to 30x energy efficiency and 50x faster computation compared to conventional digital approaches, with substantially reduced cooling requirements and operational costs. The NPS ships in a standard 19" rack form factor with PCIe Gen4 integration.
This is directly relevant to AI inference throughput. If photonic computing scales as projected, the compute density available to train and serve AI models will undergo the same kind of step-change that GPUs brought to traditional computing. The models that require massive infrastructure today will run efficiently on hardware that fits in a datacenter shelf, or eventually something much smaller.
The phone is shrinking. And photonics is one of the blades doing the cutting.
The Architecture Whisperers: OpenMythos and the Open Reconstruction Problem
Anthropic has never published a technical paper on Claude Mythos. That opacity is intentional. The architecture of a frontier model is genuinely valuable intellectual property. But last week, an open-source project called OpenMythos emerged on GitHub from researcher Kye Gomez with a specific and falsifiable hypothesis: Claude Mythos is a Recurrent-Depth Transformer (RDT), also known in the literature as a Looped Transformer.
The core claim is architecturally significant. A standard transformer scales capability by adding more layers and more parameters. A Recurrent-Depth Transformer instead recycles the same transformer block across multiple iterations, effectively performing "more thinking" with fewer weights. The hypothesis proposes that 770M parameters in an RDT architecture can match the performance of a conventional 1.3B parameter model.
OpenMythos is a hypothesis rendered in code, not a leaked weight file. But that almost makes it more interesting from a security perspective.
The community is doing architecture reverse engineering. Without access to weights, without insider knowledge, researchers are constructing principled guesses about how frontier models work and publishing those guesses as executable PyTorch. If the hypothesis is even partially correct, it accelerates the path for smaller teams, or less scrupulous actors, to build architecturally similar models without the training compute that went into the original.
This is the open-source proliferation dynamic playing out at the architectural layer, not just the weight layer.
The Chinese Open-Source Strategy
The pressure to open-source is not coming only from Western researchers. This week, Chinese AI startup Moonshot AI released Kimi K2.6 as open-source, claiming benchmark performance on par with or exceeding closed systems including GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro. The release comes as a coalition of Chinese tech giants including Alibaba, ByteDance, and Tencent issued a joint consensus backing open-source AI, even as some simultaneously invest in closed architectures.
The strategic picture here is layered. Chinese AI firms are releasing capable frontier models as open-source at a pace that is compressing the capability gap. Each open release becomes a foundation others can fine-tune, distill, or weaponize. Kimi K2.6 brought specific improvements in long-horizon coding, agent-based workflows, and front-end generation, capabilities that have direct offensive utility in the right hands.
The geopolitical dimension matters here. Nation-state cyber programs don't need to train a model from scratch when openly available weights are competitive with closed commercial systems. They fine-tune. They specialize. They distill the capability down into something purpose-built and harder to attribute.
Voice Is the New Surface: xAI Enters the Audio Stack
xAI this week launched standalone Grok Speech-to-Text and Text-to-Speech APIs, now generally available and built on the same infrastructure powering Grok Voice across Tesla vehicles, mobile apps, and Starlink customer support. The STT API supports 25 languages, word-level timestamps, speaker diarization, multichannel audio, and 12 audio formats. Pricing sits at $0.10/hour for batch and $0.20/hour for streaming.
This entry into the audio API market, competing directly with ElevenLabs, Deepgram, and AssemblyAI, represents AI capability being further commoditized into building blocks. Voice is now a cheap, accessible interface primitive.
From a threat research lens, the commoditization of high-quality speech synthesis and recognition is the final piece of a social engineering toolkit. Combined with locally-run LLMs, you now have a device that can conduct voice-based impersonation offline, without any network telemetry leaving the device. Vishing campaigns, synthetic identity creation, real-time impersonation of trusted figures: the voice component no longer requires a subscription to a cloud provider that might log the activity.
The attack surface is not just widening. It's going dark.
The Real Thesis: "Who Has the Better Weights"
The original cyber cat-and-mouse dynamic was about tools and techniques. Attackers found new exploits. Defenders patched. Attackers pivoted to living-off-the-land. Defenders built behavioral detections. The cycle churned.
The AI arms race is reshaping that dynamic. The new axis of competition is not a specific exploit or a specific technique. It's model quality, training data, and architectural efficiency. The question "who wins" is increasingly a question of who has the better weights and who can run them smaller and faster.
This is where the Mythos thread becomes genuinely concerning. Claude Mythos represents a specific kind of breakthrough, a model that achieves frontier-tier reasoning at a scale that defies what anyone expected from parameter counts of that size. The efficiency gains are architectural, not just scale-dependent. If OpenMythos's RDT hypothesis is directionally correct, that architectural insight is now in the public domain.
Nation-state programs, particularly those with domestic AI development mandates and existing signals intelligence infrastructure, are not building Mythos. But they are watching it. They are studying the architecture theories, monitoring the open-source reconstructions, and fine-tuning capable base models on specialized corpora that would make a commercial AI alignment team uncomfortable.
A Mythos-class model, running on a Pocket Lab equivalent device, purpose-trained on social engineering, vulnerability research, or infrastructure reconnaissance: that's the scenario worth gaming out. Not because it exists today in that exact form, but because every component needed to build it is available, shrinking, and becoming cheaper.
The phone in the 1980s was a status symbol because almost no one had one. The phone today is a surveillance device, a payment terminal, a social manipulation engine, and a pocket computer carried by billions of people who don't think twice about what it is.
AI is on the same trajectory. The thing that required a hyperscaler is becoming the thing that requires a backpack. Then a pocket. Then, presumably, something you don't notice you're carrying at all.
The phone is shrinking. The question is what's running on it when it does.
What Defenders Should Be Thinking About
The traditional detection surface assumes AI is cloud-bound. Log the API calls. Monitor the egress. Block the known model provider endpoints. That posture already has holes, and they're getting larger.
A few considerations worth building into your threat models now:
Offline AI inference is no longer a research novelty. Devices capable of running frontier-scale models locally are shipping to consumers in 2026. Your DLP and network monitoring posture may have implicit assumptions about AI requiring cloud connectivity. Those assumptions need revisiting.
The open-source model landscape is a supply chain problem. Fine-tuned derivatives of Kimi, Llama, Mistral, and Qwen are proliferating. Attribution of AI-assisted attacks will become more complex as the base models diversify. The "which model was used" forensic question will get harder, not easier.
Voice synthesis is commodity. The cost and accessibility of high-quality real-time voice synthesis has crossed a threshold. Defensive training around voice-based social engineering needs to catch up with the technical baseline that attackers now have access to.
Architecture research is proliferation. OpenMythos isn't a threat. But the pattern of community reverse-engineering frontier architectures is a preview of how capability diffuses. The gap between "what the frontier labs have" and "what everyone else can build" is narrowing faster than most security programs are accounting for.
The arms race is real. The phone is shrinking.
References:
- Tiiny AI Pocket Lab: tiiny.ai | PowerInfer on GitHub
- Q.ANT Native Processing Server: qant.com/photonic-computing
- OpenMythos: MarkTechPost, April 19, 2026
- Moonshot AI Kimi K2.6: South China Morning Post, April 21, 2026
- xAI Grok STT/TTS APIs: MarkTechPost, April 18, 2026